Von (Predictive Solutions)
Dieses Verfahren soll denjenigen das Leben erleichtern, die mit großen Datensätzen arbeiten und Regressionsmodelle verwenden möchten. Bei automatischen linearen Modellen fehlen viele erweiterte Einstellungen und Optionen für die Modelluntersuchung, die in anderen Regressionsverfahren zu finden sind. Andererseits beschleunigt und rationalisiert es, wie andere Verfahren dieser Art auch, die Datenverarbeitung.
Was sind die Unterschiede?
Die Regressionsanalyse in PS IMAGO PRO verwendet traditionell das Verfahren der linearen Regression in SPSS Statistics (REGRESSI0N). Ab der Version 19 verfügt SPSS Statistics jedoch über eine zusätzliche Prozedur, nämlich LINEAR. Diese Prozedur wird häufig für prädiktive Analysen verwendet und wird in diesem und den folgenden Blogbeiträgen im Mittelpunkt stehen. Beide Regressionsmethoden haben Vor- und Nachteile, Befürworter und Gegner. Heute werden wir uns auf die potenziellen Vorteile des LINEAR-Verfahrens konzentrieren und zeigen, wie man ein einfaches Modell erstellt und dessen Ergebnisse verwendet.
Das traditionelle Regressionsverfahren bietet zahlreiche Techniken zur Auswahl von Variablen für das Modell. Diese Techniken gehören zur Familie der progressiven Methoden (z. B. schrittweise, Vorwärtsauswahl oder Rückwärtselimination). Die Auswahl der Variablen erfolgt automatisch anhand statistischer Kriterien, nämlich einer Folge von t- oder F-Tests. Das LINEAR-Verfahren stellt zusätzlich eine Methode zur Verfügung, die als alle möglichen Teilmengen bezeichnet wird.
Das Regressionsmodell (REGRESSION) ermöglicht es dem Analysten, eine eingehende Analyse von Ausreißern und beeinflussenden Beobachtungen durchzuführen. Statistiken wie Cooks Distanz oder DFBETAS können im Datensatz gespeichert werden, was bei der automatischen Generierung eines Modells mit der Funktion LINEAR nicht möglich ist. Stattdessen werden solche Beobachtungen bei der Erstellung des Modells behandelt, d. h. die Anwendung entscheidet automatisch, welche Beobachtung als Ausreißer betrachtet werden sollte.
Das dritte Merkmal des LINEAR-Verfahrens ist die Möglichkeit, so genannte Ensemble-Modelle zu erstellen, zum Beispiel durch Bagging oder Boosting.
Sein vierter Vorteil ist die Möglichkeit, es an die Verarbeitung großer Datensätze anzupassen. Dies erfordert jedoch PS IMAGO PRO in einem Client/Server-Setup.
Was ist darin enthalten?
Zunächst werfen wir einen Blick auf die Schnittstelle des Fensters Automatische lineare Modellierung und seine Ergebnisobjekte. Wir werden uns auch die Optionen für die automatische Vorbereitung der Daten ansehen, die für das Verfahren zur Verfügung stehen. Anschließend werden wir uns mit den Methoden zur Auswahl von Prädiktoren und zur Erstellung von Ensemblemodellen befassen.
Zur Veranschaulichung werden wir ein Beispiel-Regressionsmodell erstellen, um zu überprüfen, ob es eine lineare Beziehung zwischen den Verkäufen von Musik-CDs und folgenden Merkmalen gibt:
- Bewertung der Künstler im Publikum
- Werbeausgaben
- Anzahl der Hörspiele
Das Verfahren ist im Menü Analysieren > Regression > Automatische lineare Modellierung zu finden. Gehen Sie auf die Registerkarte Felder und wählen Sie Variablen für die Analyse aus.

Eine weitere Ähnlichkeit ist die Möglichkeit, eine Rolle für eine Variable zu deklarieren (Data Editor > Variable View > Role). Wenn Sie eine Rolle als Input oder Target deklarieren, wird die automatische lineare Modellierung die Variablen automatisch in die entsprechenden Felder setzen.

Gehen Sie auf die Registerkarte Build Options. Die Liste auf der linken Seite zeigt eine Reihe von Optionsgruppen an. Heute konzentrieren wir uns auf Grundlagen, wo Sie die automatische Datenaufbereitung aktivieren können, wie in Abb. 2 dargestellt. Die meisten der Transformationen verbessern die Vorhersagekraft des Modells. Wenn Sie diese Option aktivieren, wird das Modell aus den verarbeiteten Werten und nicht aus den ursprünglichen Variablen erstellt. Die verwendeten Transformationen werden zusammen mit dem Modell gespeichert. Folgende Transformationen werden bei aktivierter Option durchgeführt:
- Datums- und Zeitbehandlung – Datums- und Zeitprädiktoren werden in eine Dauer umgewandelt, z. B. eine Anzahl von Monaten ab heute.
- Anpassung des Messniveaus – Variablen, die als quantitative Variablen mit weniger als fünf eindeutigen Werten deklariert sind, werden als ordinale Variablen behandelt. Ordinale Variablen mit mehr als zehn Kategorien werden als quantitative Variablen behandelt.
- Behandlung von Ausreißern – Werte, die nicht innerhalb von +/- drei Standardabweichungen vom Mittelwert liegen, werden als Ausreißer betrachtet.
- Umgang mit fehlenden Werten – fehlende Werte bei qualitativen Variablen werden bei einer Nominalskala durch einen Modalwert und bei einer Ordinalskala durch einen Medianwert ersetzt. Fehlende Werte in quantitativen Variablen werden durch einen Mittelwert ersetzt.
- Überwachtes Merging – bevor qualitative Variablen im Modell verarbeitet werden, überprüft das System, ob es für die Vorhersage der Zielvariable wichtig ist, Informationen über alle Kategorien in einer Variablen zu erhalten oder nicht. Handelt es sich bei dem Prädiktor um eine qualitative Variable (z. B. Bildung), können Sie überprüfen, ob die ermittelten Kategorien korrekt sind. Unterscheiden die Bildungskategorien das Einkommen gut? Zu viele detaillierte Kategorien können es erschweren, allgemeine Abhängigkeiten zu erkennen. Bei Regressionsmodellen werden qualitative Variablen in eine Reihe boolescher Variablen umgewandelt, bevor sie verwendet werden. Wenn Sie Variablen mit weniger Kategorien verwenden, vereinfachen und verallgemeinern Sie das Modell. Variablen, deren Kategorien die vorhergesagte Variable nicht differenzieren, werden im Modell nicht verwendet.
Sie können außerdem das Konfidenzintervall festlegen, bei dem die Intervallschätzung der Modellparameter durchgeführt wird. Es liegt normalerweise zwischen 0,9 und 0,99.
Gehen Sie zur Registerkarte Modelloptionen. Hier können Sie Entscheidungen bezüglich der Speicherung des Modells treffen. Wenn Sie möchten, dass das vorhergesagte Umsatzvolumen in den Datensatz aufgenommen wird, müssen Sie die erste Option aktivieren, die standardmäßig deaktiviert ist: Speichern Sie vorhergesagte Werte im Datensatz, und wählen Sie einen Namen für die Variable mit dem vorhergesagten Wert.


Die Modellzusammenfassung
Die Zusammenfassung zeigt allgemeine Informationen über das Modell und das angepasste R2 in Form eines Balkendiagramms an. Wir erhalten 65,2 %, was je nach Bereich zufriedenstellend sein kann.
Durch einen Doppelklick auf den Bericht öffnen Sie ein Modellbetrachtungsfenster, in dem Sie weitere Ergebnisse sehen können. Sie navigieren durch den Bericht, indem Sie auf die Objekte auf der linken Seite klicken. Das erste Objekt haben wir bereits gesehen, also sehen wir uns an, was weiter unten ist.

Das zweite Objekt zeigt eine Zusammenfassung der automatischen Datenaufbereitung. Alle drei Prädiktoren wurden von den Ausreißer-Erkennern akzeptiert und zur Erstellung des Modells verwendet. Das nächste Objekt zeigt ein Diagramm zur Bedeutung der Prädiktoren.

Die Wichtigkeit der Prädiktoren ist das Maß für den Einfluss der Variablen auf die vorhergesagten Werte (nicht für die Genauigkeit der Vorhersage). Die Summe der Wichtigkeitswerte aller Prädiktoren ist 1. Dieses Modell wird hauptsächlich vom Werbebudget (0,48) und der Anzahl der Hörspiele im Radio (0,47) dominiert. Die Künstlerbewertung ist für die Vorhersage weniger wichtig (0,05).



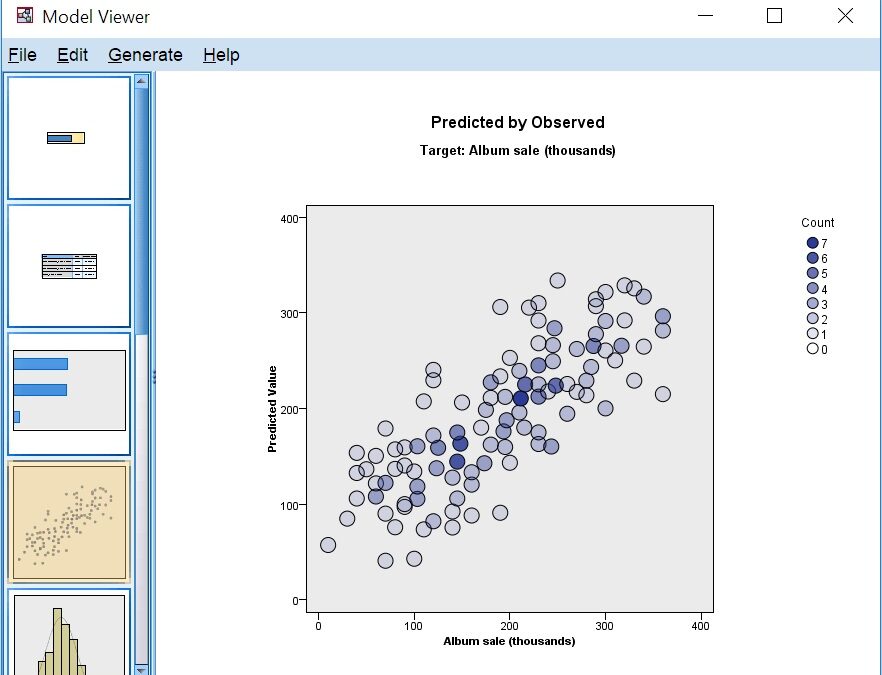
Zusätzliche Ergebnisse werden mit drei anderen Formen der Visualisierung gezeigt. Erstens, das Streudiagramm der vorhergesagten Verkäufe und des tatsächlichen Ergebnisses. Würde das Modell den Wert jeder Beobachtung perfekt vorhersagen, würden die Punkte auf einer 45-Grad-Linie liegen. Unter den diagnostischen Diagrammen gibt es zwei Diagramme zur Überprüfung der Normalität oder der Restverteilung. Sie können ein Histogramm der (studentisierten) Residuen mit einer angepassten Normalverteilungskurve oder ein P-P-Diagramm für die Verteilung auswählen. Da wir Trainingsdaten verwenden, bestätigen beide Diagramme eine Normalverteilung, was nicht immer der Fall ist.

Diese Liste enthält IDs einzelner Datensätze, die das Modell stark beeinflussen und vom Algorithmus als Ausreißer betrachtet wurden. Wenn wir einer Variablen, z. B. dem Albumnamen, eine Rolle zugewiesen haben (Dateneditor > Variablenansicht > Rolle), wird diese in der Spalte Datensatz-ID verwendet. Ein hoher Wert der Cook’schen Distanz zeigt an, dass das Album die Modellparameter stark beeinflussen könnte, wenn es aus der Analyse entfernt würde. Das Kriterium, um eine Beobachtung als starken Einflussfaktor zu betrachten, ist die Faustregel von Fox, die besagt, dass die Cook’sche Distanz 4/N-pc nicht überschreiten sollte, wobei N der Stichprobenumfang und pc die Anzahl der Modellparameter ist.
Obwohl automatische Verfahren umstritten sind, können sie nützlich sein. Dieser Ansatz ist in der Regel für große Datensätze zu rechtfertigen, bei denen automatische Verfahren die Nutzung der Rechenleistung für die Suche und die vorläufige Untersuchung der Daten erleichtern. In künftigen Beiträgen werden wir uns näher mit der Modellerstellung und den Optionen befassen, die Sie bei der Erstellung von Modellen mit automatischer linearer Modellierung ändern können.