Von WIKTORIA KORYGA (Predictive Solutions)
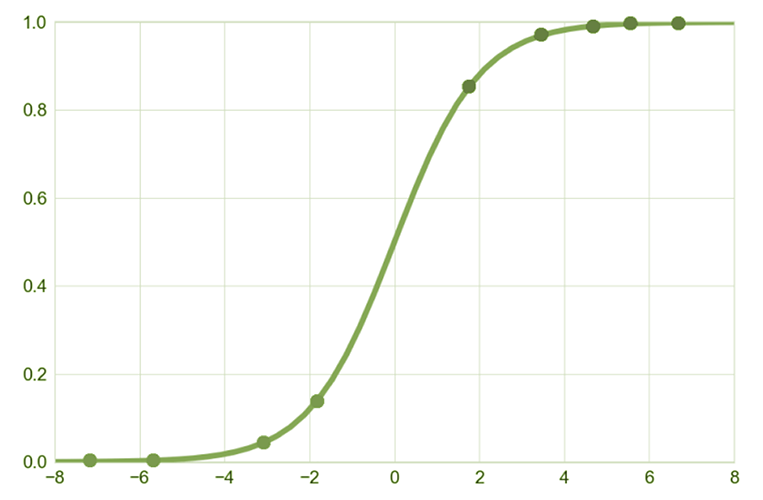
In der Praxis ist die einfachste und am häufigsten verwendete Art der Regression das lineare Regressionsmodell, dessen Parameter nach der Methode der kleinsten Quadrate geschätzt werden. Die lineare Regression wird jedoch nur zur Vorhersage einer kontinuierlichen Variable verwendet. Was aber, wenn wir eine Variable vorhersagen wollen, die nur zwei Werte hat? Ein Analyst steht nicht selten vor der Herausforderung, verschiedene Ereignisse vorherzusagen, z. B. ob eine Person einen aufgenommenen Kredit zurückzahlen wird, ob ein Kunde ein bestimmtes Unternehmen verlässt oder ob es sich bei einer E-Mail um Spam handelt oder nicht. Das Ereignis, das wir vorhersagen wollen (die abhängige Variable), ist ein Null-Eins-Ereignis – etwas wird eintreten oder nicht eintreten. Die Lösung des Analysten in solchen Situationen ist die logistische Regression, bei der die abhängige Variable nur zwei Werte hat.WIE VERSTEHEN WIR WAHRSCHEINLICHKEIT UND ZUFALL?
Die logistische Regression ist eine Technik, die auf der Wahrscheinlichkeit und dem Zufall des Eintretens eines Ereignisses beruht. Wahrscheinlichkeit und Zufall sind in der Statistik zwei unterschiedliche Konzepte, und es ist notwendig, den Unterschied zwischen ihnen zu verstehen, um das logistische Regressionsmodell in Analysen korrekt verwenden zu können. Die Wahrscheinlichkeit gibt die Gewissheit des Auftretens eines Phänomens an. Sie wird auf der Grundlage der Häufigkeit des Auftretens eines bestimmten Ereignisses unter allen möglichen Ereignissen berechnet. Die Wahrscheinlichkeit (oder Quote) ist das Verhältnis zwischen der Wahrscheinlichkeit, dass ein Ereignis eintritt, und der Gewissheit, dass das entgegengesetzte Ereignis eintritt, d. h. das Verhältnis zwischen der Wahrscheinlichkeit, dass ein Ereignis eintritt, und der Wahrscheinlichkeit, dass es nicht eintritt

 wobei:
wobei: UNABHÄNGIGE VARIABLEN IN EINEM LOGISTISCHEN REGRESSIONSMODELL
Die unabhängigen Variablen in einem logistischen Regressionsmodell können sowohl quantitative als auch qualitative Variablen sein. Wenn jedoch qualitative Variablen in das Modell aufgenommen werden, ist es notwendig, sie entsprechend zu „behandeln“. Eine solche Variable muss entsprechend kodiert werden – zum Beispiel wird Frauen der Wert „0“ und Männern der Wert „1“ zugewiesen. Dann müssen wir entscheiden, welche Kategorie der qualitativen Variable unser Bezugspunkt sein wird – ob wir an der Interpretation der Ergebnisse für Männer im Vergleich zu Frauen interessiert sind oder andersherum. Wenn die qualitative Variable mehr als zwei Kategorien hatte, geben wir auch an, welche Kategorie unsere Referenzkategorie in der Analyse sein wird.ANNAHMEN ZUR LOGISTISCHEN REGRESSION
Bevor man mit der Analyse der logistischen Regression beginnt, ist es wie bei jeder statistischen Technik wichtig zu prüfen, ob die Annahmen erfüllt sind. Die logistische Regression hat im Vergleich zur multiplen Regression relativ wenige Annahmen. Hier sind einige von ihnen:
- Binäre Form der abhängigen Variable,
- Keine Korrelation zwischen den unabhängigen Variablen,
- Eine lineare Beziehung zwischen dem Logit der Wahrscheinlichkeit und den unabhängigen Variablen (der natürliche Logarithmus der Wahrscheinlichkeit ist linear von der erklärenden Variable abhängig),
- Einbeziehung nur derjenigen unabhängigen Variablen in das Modell, die einen signifikanten Einfluss auf die abhängige Variable haben.
EIN BEISPIEL FÜR DIE PRAKTISCHE ANWENDUNG DER LOGISTISCHEN REGRESSION
Wir werden nun die Möglichkeit untersuchen, ein logistisches Regressionsmodell zu verwenden, um vorherzusagen, ob eine Person ihren Vertrag mit einem Telekommunikationsanbieter verlängern wird. Ein Beispiel für die Verwendung der logistischen Regression wurde in PS IMAGO PRO vorbereitet. Die abhängige Variable in der Analyse ist die Variable, die angibt, ob die Person den Vertrag für Telekommunikationsdienste mit einem bestimmten Unternehmen erneuert hat (wobei „1“ – wird erneuert, „0“ – wird nicht erneuert). Aus der Häufigkeitstabelle geht hervor, dass insgesamt 200 Personen im Datensatz enthalten sind. Der Vertrag wurde von 95 Personen verlängert, was 47,5 % aller Personen mit einem Vertrag mit einem bestimmten Dienstanbieter entspricht.
Tabelle 1. Häufigkeitstabelle für die Variable Vertragsverlängerung




Betrachten wir nun, was ein negativer B-Koeffizient bei der Variable Geschlecht bedeutet. In unserem Beispiel wurden Männer mit einem Wert von „1“ und Frauen mit einem Wert von „0“ gekennzeichnet. Wir analysieren also Männer im Vergleich zu Frauen. Ein negativer B-Koeffizient bedeutet hier, dass die Wahrscheinlichkeit, dass ein Mann seinen Vertrag verlängert, geringer ist als die Wahrscheinlichkeit, dass eine Frau ihren Vertrag verlängert.
Um herauszufinden, um wie viel geringer diese Chance ist, ziehen wir den Wert des Odds Ratio in der letzten Spalte der Tabelle heran – Exp(B). Das Odds Ratio in der logistischen Regression ist ein Schlüsselbegriff im Zusammenhang mit der Interpretation der Ergebnisse. Er definiert die Veränderung der Wahrscheinlichkeit, dass der Wert einer bestimmten erklärenden Variablen eintritt, wenn die erklärende Variable um eine Einheit zunimmt, unter der Annahme, dass die übrigen unabhängigen Variablen konstant bleiben. Wir berechnen den Odds-Quotienten ![]()
![]() als das Verhältnis der Wahrscheinlichkeiten für das Eintreten eines bestimmten Ereignisses in zwei Gruppen. Aufgrund der verwendeten Werte wird er wie folgt interpretiert:
als das Verhältnis der Wahrscheinlichkeiten für das Eintreten eines bestimmten Ereignisses in zwei Gruppen. Aufgrund der verwendeten Werte wird er wie folgt interpretiert:
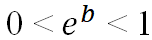
 – die negativen Auswirkungen einer Variablen auf das Eintreten eines Ereignisses,
– die negativen Auswirkungen einer Variablen auf das Eintreten eines Ereignisses,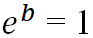
 – das Fehlen des Einflusses einer Variable auf das Eintreten eines Ereignisses,
– das Fehlen des Einflusses einer Variable auf das Eintreten eines Ereignisses,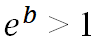
 – positive Auswirkungen auf das Eintreten des Ereignisses.
– positive Auswirkungen auf das Eintreten des Ereignisses.
Der Odds-Ratio-Wert für die Geschlechtsvariable beträgt 0,202 und besagt, dass die Wahrscheinlichkeit, dass Männer ihren Vertrag verlängern, um 80 % geringer ist als bei Frauen.
Das Alter ist der zweite signifikante Prädiktor für die Vorhersage von Vertragsverlängerungen. Der B-Wert für das Alter beträgt 0,057, während das Odds Ratio 1,059 beträgt, was bedeutet, dass die Wahrscheinlichkeit einer Vertragsverlängerung um das 1,059-fache steigt, wenn das Alter der Person um ein Jahr steigt.
Betrachten wir abschließend die Klassifizierungstabelle für das logistische Regressionsmodell mit einer Konstante und den eingeführten Prädiktoren Alter und Geschlecht (die nicht signifikante Variable Telefon wurde ausgeschlossen). Beachten Sie, dass der Ausschluss der unbedeutenden Variable aus der Analyse zu einem Anstieg des Prozentsatzes der richtigen Klassifizierungen auf etwa 71 % führte.

ZUSAMMENFASSUNG
Die logistische Regressionsanalyse ist ein statistisches Verfahren, das wir in vielen wissenschaftlichen und geschäftlichen Bereichen einsetzen können. Die abhängige Variable in einem logistischen Regressionsmodell ist eine binäre Variable, während die Prädiktoren sowohl kontinuierliche als auch kategoriale Variablen sein können.
Die logistische Regression ermöglicht es, die Auswirkungen mehrerer unabhängiger Variablen auf die Wahrscheinlichkeit des Eintretens eines Ereignisses zu bewerten. Sie wird häufig in der Medizin verwendet, z. B. um Risikofaktoren für postoperative Komplikationen oder das Auftreten einer bestimmten Krankheit zu ermitteln, oder im Bankwesen zur Einschätzung des Kreditrisikos usw.
[1] Das Signifikanzniveau, unterhalb dessen die Prädiktoren als statistisch signifikant angesehen wurden, wurde auf 0,05 festgelegt.