Von NATALIA GOLONKA (Predictive Solutions)
Kann ein einziges abnormales Ereignis Anlass zur Sorge geben? Sollte aufgrund einer einzigen Abweichung von der Norm ein rotes Licht blinken? Ja, natürlich! In vielen Branchen und Unternehmen ist eine Anomalie ein Zeichen, auf das schnell und effizient reagiert werden muss, um Folgen zu vermeiden. Wie erkennt man also eine Anomalie und wie kann man sie nicht mit einem gewöhnlichen Ausreißer verwechseln? Wir stellen Methoden zur Erkennung anomaler Beobachtungen und die Bedeutung von Anomalien in der Wirtschaft vor.AUSREISSER VS. ANOMALIE
Bei der Untersuchung oder Vorbereitung von Daten für die weitere Analyse stößt man häufig auf Beobachtungen, die nicht ganz zum Rest des Datensatzes passen. Diese Atypizität kann auf eine fehlerhafte Messung oder Aufzeichnung eines Wertes zurückzuführen sein, z. B. ein negatives Alter des Befragten, eine Prüfungsnote über 100 % oder ein anderer statistischer Fall. In einem solchen Fall spricht man von einem atypischen Wert oder im Extremfall von einer Ausreißerbeobachtung. Eine ausführliche Diskussion über ihre Identifizierung und Bedeutung in der Datenanalyse finden Sie im Artikel über Ausreißer. Wenn wir eine Beobachtung als Ausreißer identifizieren, setzt dies voraus, dass wir irgendwie mit ihr umgehen wollen, d. h. sie aus dem Datensatz eliminieren oder ihren Wert an den Rest der Beobachtungen anpassen. Eine solche Wertsubstitution kann mit mehr oder weniger ausgefeilten Methoden erfolgen. Die einfachste Lösung besteht darin, den Mittelwert oder eine andere einfache Statistik zu verwenden und den abnormalen Wert damit zu ersetzen. Diese Methode kann jedoch problematisch sein, wenn es mehr solcher Beobachtungen gibt, da eine große Anzahl von Wertanpassungen die Verteilungen der einzelnen Variablen verzerrt, was in weiteren Schritten zu fehlerhaften Modellergebnissen führt. Ein alternativer Ansatz ist die zufällige Ziehung von Werten aus bestimmten Bereichen oder die Verwendung der oben erwähnten fortgeschritteneren Techniken, die beispielsweise auf Algorithmen aus dem Bereich des Data Mining basieren. Manchmal ist das Erkennen ungewöhnlicher Werte jedoch ein Selbstzweck. Manchmal ist das Auftreten solcher Beobachtungen kein Zufall. Situationen, die dies gut veranschaulichen, sind beispielsweise medizinische Bildgebungsverfahren, wie die Erkennung von Tumoren auf Röntgenbildern. Ein anderer Bereich sind ungewöhnliche Verhaltensweisen bei Bankkonten, die auf Betrug hindeuten können. In den genannten Beispielen haben wir es nicht mehr mit einem Ausreißer zu tun, da wir ihn bei nachfolgenden Datenanalyseschritten wie der Modellierung nicht eliminieren oder ersetzen werden. Die Suche nach solchen wichtigen Ausreißern wird zum eigentlichen Ziel, und sie werden dann als Anomalien bezeichnet.ERKENNUNG VON ANOMALIEN
Die Erkennung von Anomalien ist sicherlich eine große Herausforderung für jeden Analysten. Zu diesem Zweck können verschiedene Techniken aus dem Bereich des Data Mining eingesetzt werden, aber auch einfachere Methoden. Die wichtigste Frage ist jedoch, ob die Erkennung von Anomalien auf vorhandenen Daten basieren soll oder nicht. Wir können Algorithmen des überwachten Lernens verwenden, wenn wir über ausreichende historische Daten verfügen. Früher festgestellte Anomalien sollten gekennzeichnet werden, und obwohl dieser Prozess sehr zeitaufwändig sein kann, lohnt er sich auf jeden Fall, da dieses Wissen die Chancen erhöht, Anomalien in Zukunft vorherzusagen und genau zu erkennen. Solche Methoden könnten Techniken aus dem Bereich des maschinellen Lernens sein, die auf Klassifikatoren wie Entscheidungsbäumen oder den fortschrittlicheren Random Forests oder XGBoost beruhen. Etwas schwieriger ist die Situation, wenn wir in unseren Daten keinen „Lehrer“ zur Verfügung haben, d. h. wenn bisher keine Anomalien gekennzeichnet wurden. In diesem Fall müssen unüberwachte Lernmethoden verwendet werden, bei denen die Algorithmen selbst kontinuierlich bewerten müssen, welche Beobachtung eine Anomalie sein könnte. Zu diesen Methoden gehören der klassische Anomalie-Algorithmus oder die Isolation Forest-Technik, die ebenfalls auf Entscheidungsbäumen basiert. Wie entscheiden wir nun, welchen Ansatz wir für die Suche nach einer Anomalie verwenden? Wie immer hat jede Lösung ihre Stärken und Schwächen.ANOMALIEN IN ÜBEREINSTIMMUNG MIT DEN REGELN
Algorithmen des überwachten Lernens folgen vorgegebenen Regeln und identifizierten Mustern von Anomalien. Auf diese Weise können wir mit hoher Effizienz nach erwarteten Anomalien suchen. Dieser Ansatz eignet sich beispielsweise gut für Modelle, die diagnostische Bilddaten analysieren. Das Bildmuster einer Krebsläsion ist ziemlich gut entwickelt, die Diagnosekriterien sind klar, präzise und im Laufe der Zeit relativ stabil. Die Verfügbarkeit historischer Daten ist in einem solchen Fall ein großer Vorteil. Problematisch wird es jedoch, wenn die Regeln für die Anomalie nicht genau festgelegt sind oder gar nicht festgelegt werden können. Im Gegensatz zu dem zitierten Beispiel der diagnostischen Bildgebung sind einige Anomalien nicht so leicht zu definieren. Eine solche Situation könnte die Aufdeckung von Finanzbetrug in Bankensystemen sein. Die erste Herausforderung ist die Definition selbst – reicht es aus, wenn jemand einen aufgenommenen Kredit nicht zurückzahlt? Eine solche Entwicklung liegt nicht immer in der Absicht des Verbrauchers, so dass es schwer sein wird, dies im Voraus zu erkennen (hier kommt natürlich eher die Frage der Risikobewertung vor einer Kreditentscheidung in den Sinn). Sollten wir also nur solche Datensätze als betrügerisch kennzeichnen, bei denen eine gerichtliche Entscheidung ergangen ist? Hier kommen wir zum zweiten Problem, nämlich der Schwierigkeit, einen ausreichend großen Satz solcher Daten zu beschaffen. Unter den Millionen von Bankkunden ist der Anteil solcher Anomalien wahrscheinlich zu gering, als dass Algorithmen des überwachten Lernens ein sinnvolles Modell entwickeln könnten.ANOMALIEN, DIE NICHT DEN REGELN ENTSPRECHEN
Ein alternativer Ansatz ist die Verwendung von Modellen, die auf unüberwachtem Lernen basieren. In diesem Fall gibt es im Datensatz keine Markierungsvariable für die bisher entdeckten Anomalien. Ihre Erkennung basiert daher nicht auf zuvor eingeführten Regeln, sondern auf der Suche nach Beobachtungen, die von dem typischen Muster abweichen, das das Modell für diese Daten erstellt hat. Solche Algorithmen können riesige Datenmengen verarbeiten – sowohl im Hinblick auf die Anzahl der Beobachtungen als auch auf die Anzahl der Variablen. Da es nicht notwendig ist, ausgearbeitete Regeln zu verwenden, und somit auch nicht notwendig ist, sich auf einige wenige oder mehrere Variablen zu beschränken, auf denen solche Regeln basieren, sind Algorithmen, die auf unüberwachtem Lernen basieren, ein großartiges Werkzeug für die Entdeckung neuer multivariater Muster von Anomalien.
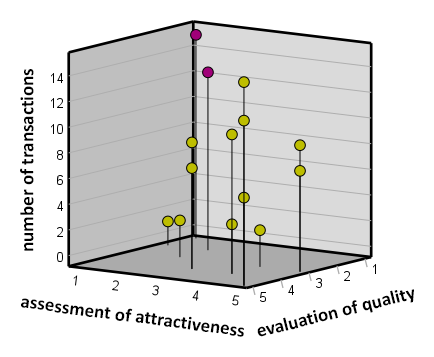
Abbildung 1. Zwei potenzielle Anomalien sind lila hervorgehoben – Kunden, die eine relativ hohe Anzahl von Transaktionen trotz einer sehr niedrigen Bewertung der Qualität und Attraktivität des und Attraktivität des Produkts abschlossen.
ZUSAMMENFASSUNG
Die Erkennung von Anomalien kann nicht nur ein wichtiger Schritt in der Datenanalyse sein, sondern auch zum Selbstzweck werden. Wenn wir wissen, nach welchen Anomalien wir in einem Datensatz suchen, können wir überwachte Modelle verwenden, die solche Anomalien effektiv erkennen. Wenn wir nicht wissen, welche anomalen Beobachtungen zu erwarten sind, ist es besser, unüberwachte Modelle zu verwenden, die die Erkennung von Anomalien auf mehrdimensionale und regelfreie Weise angehen. Dabei ist jedoch zu bedenken, dass solche Modelle zu den explorativen Methoden gehören, so dass die erzielten Ergebnisse überprüft werden müssen. In der Praxis wird häufig ein hybrider Ansatz verwendet, bei dem wir das bereits vorhandene Wissen aus historischen Daten nutzen, um Anomalien zu erkennen, die bestehende Muster wiederholen, und Algorithmen, die neue, bisher unentdeckte Muster aufdecken können.