Von NATALIA GOLONKA (Predictive Solutions)
Can one abnormal occurrence cause concern? Based on one deviation from the norm, should a red light start flashing? Of course! In many industries and businesses, an anomaly is a sign that must be reacted to quickly and efficiently in order to prevent consequences. So how do you recognise an anomaly and how do you not mistake it for an ordinary outlier? We present methods for detecting anomalous observations and the importance of anomalies in business.OUTLIER VS ANOMALY
When exploring or preparing data for further analysis, it is common to come across observations that do not quite fit with the rest of the dataset. This atypicality may be due to an erroneous measurement or recording of a value, e.g., a negative age of the respondent, an exam score above 100% or some other statistical case. In such a situation, we can speak of an atypical value or, in extreme cases, an outlier observation. For a detailed discussion of their identification and significance in data analysis, see the article on outliers. If we identify an observation as an outlier, this assumes that we will want to deal with it somehow, i.e., eliminate it from the data set or adjust its value to the rest of the observations. Such value substitution can be done using more or less sophisticated methods. The simplest solution is to use the mean or another simple statistic and substitute it for the abnormal value. However, this method can be problematic if there are more such observations, as a large number of value adjustments will distort the distributions of the individual variables, leading to erroneous model results at further stages. An alternative approach is to randomly draw values from specific ranges or to use the aforementioned more advanced techniques based, for example, on algorithms from the field of data mining. Sometimes, however, identifying unusual values is an end in itself. Sometimes, the appearance of such observations is no coincidence. Situations that illustrate this well are, for example, medical imaging techniques, such as the detection of tumours on X-rays. Another area is unusual behaviour in bank accounts, which may be indicative of fraud. In the examples given, we are no longer dealing with an outlier, as we will not be eliminating or substituting it for subsequent data analysis steps such as modelling. Finding such important outlier observations becomes the aforementioned goal in itself and they are then called anomalies.ANOMALY DETECTION
Anomaly detection is certainly quite a challenge for any analyst. Various techniques from the area of data mining can be used for this purpose, as well as more basic methods. The most important issue, however, is whether or not anomaly detection will be based on existing data. We can use supervised learning algorithms if we have adequate historical data. Previously identified anomalies should be flagged, and although this process can be very time-consuming, it is certainly worthwhile as such knowledge will increase the chances of predicting and accurately detecting anomalies in the future. Such methods could be techniques from the field of machine learning based on classifiers such as decision trees, or the more advanced random forests or XGBoost based on them. A slightly more difficult situation is when we do not have a ‘teacher’ available in our data, i.e., no anomalies have been labelled so far. In this case, unsupervised learning methods must be used, in which the algorithms themselves have to continuously assess which observation might be an anomaly. Such methods include the classical anomaly algorithm or the Isolation Forest technique, also based on decision trees. So how do we decide which approach to use to look for an anomaly? As always, each solution will have its strengths and weaknesses.ANOMALIES IN ACCORDANCE WITH THE RULES
Supervised learning algorithms follow predetermined rules and identified patterns of anomalies. By using them, we can search for anomalies that are expected with high efficiency. This approach will work well, for example, in models analysing diagnostic imaging data. The image pattern of a cancer lesion is fairly well developed, the diagnostic criteria are clear, precise and relatively stable over time. Having historical data gives a huge advantage in such a case. Difficulties begin, however, if the rules for the abnormality are not or cannot even be precisely specified. In contrast to the cited example of diagnostic imaging, some anomalies will not be so easy to define. Such a situation might be the detection of financial fraud in banking systems. The first challenge is the definition itself – is it enough if someone does not repay a loan they have taken out? Such a development is not always the intention of the consumer, so it will be hard to predict this in advance (here, of course, the issue of risk assessment before a credit decision comes more to mind). So, should we only flag as fraudulent in the dataset those records where a court decision has been made? Here we come to the second problem – the difficulty of obtaining a sufficiently large set of such data. Of the millions of bank customers, such anomalies are likely to be too small a proportion for supervised learning algorithms to be able to develop a meaningful model.ANOMALIES OUTSIDE THE RULES
An alternative approach is to use models based on unsupervised learning. In this case, there is no flagging variable in the set for the anomalies detected so far. Their detection is therefore based not on previously introduced rules, but on the search for observations that deviate from the typical pattern created for this data by the model. Such algorithms can process huge amounts of data – both from the perspective of the number of observations and the number of variables. Because there is no need to use elaborated rules, and thus also no need to be limited to the few or several variables on which such rules are based, algorithms based on unsupervised learning are a great tool for discovering new multivariate patterns of anomalies.
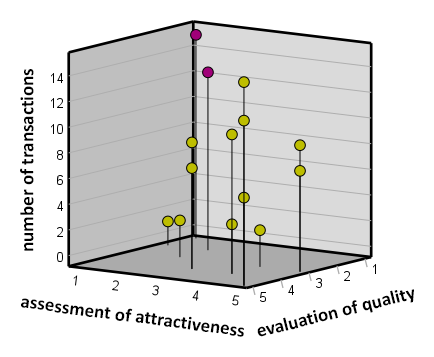
Figure 1. Two potential anomalies are highlighted in purple – customers who completed a relatively high number of transactions despite a very low rating for the quality and attractiveness of the product.
SUMMARY
The process of anomaly detection can not only be an important step in data analysis, but can also become an end in itself. If we know what anomalies we are looking for in a dataset, we can use supervised models that will effectively identify such anomalies. In the case where we do not know what anomalous observations to expect, it is better to use unsupervised models that approach anomaly detection in a multidimensional and rule-free manner. However, it should then be borne in mind that such models belong to exploratory methods, so the results obtained must be verified. In practice, a hybrid approach is often used, in which we use the knowledge we already have from historical data to detect anomalies that replicate existing patterns and algorithms that can reveal new, previously undiscovered patterns.