By RAFAŁ WAŚKO (Predictive Solutions)
Segmentation is a key process in data analysis, dividing a data set into relatively homogeneous groups based on specific criteria. The purpose of segmentation is to identify hidden patterns, differences and similarities between objects in a dataset, enabling more precise and relevant analyses. Two segmentation techniques can be distinguished within segmentation: clustering and classification.
Clustering, otherwise known as cluster analysis, is the process of dividing a set of elements into subsets (categories or groups) such that the elements within each subset are more similar to each other than to the elements outside that subset. The purpose of clustering is to look for natural structures or clusters in the data, thus identifying relationships between objects in the set. Clustering methods are particularly useful when there is no prior categorical assignment for the data being analysed.
Classification is another technique used in data segmentation. Most often in classification we have a set of variables in which individual observations are already assigned to specific target groups. Such a grouping provides a template for assigning a new observation to one of the predefined classes. Unlike clustering, classification works on data in which we have a dependent variable.
Segmentation contributes to a better understanding of data and more accurate decision-making in various fields such as marketing, economics, medicine and social sciences.
MAIN SEGMENTATION ASSUMPTIONS
Assumptions about segmentation are important in order to make the whole process a reliable tool for data analysis and decision-making in different areas, such as marketing, customer management or service personalisation. By meeting these assumptions, segmentation can provide valuable and relevant information about different groups. Different grouping techniques approach the creation of segments in different ways, but it is worth noting the following general assumptions for segmentation in this process.
- Homogeneity: This assumption implies that the elements within each group (segment) are more similar to each other than to those in other groups. In other words, segments should contain such observations that exhibit similar features and characteristics.
- Diversity: This assumption refers to the need for differentiation between segments. This means that the different groups should be significantly different from each other in terms of certain segmentation criteria. Otherwise, if the segments are too similar, they will not be sufficiently informative.
- Exclusivity: This assumption implies that each data element must be assigned to one of the segmentation groups. There should be no elements that remain unclassified or are assigned to more than one group.
- Stability: This assumption suggests that the segmentation results should be stable and reproducible across samples. This means that even if the analysis is performed multiple times on the same dataset, similar or identical groups should emerge.
GROUPING VS. CLASSIFICATION
Clustering is often used as an initial step in data analysis to identify different segments in a dataset. This process allows for an understanding of the differences and similarities between the different objects in the set, as well as the extraction of key characteristics that characterise each group. However, the clustering process itself can provide valuable information, but still does not provide solutions in specific cases as to what action should be taken against each group. Classification can be a continuation of the grouping process and involves assigning new data to existing pre-identified groups. In the case of classification, the identified patterns and characteristics that distinguish each group are used to determine to which group the new observations should be assigned. Let’s look at an example situation. We are conducting an analysis of the customer data of an online shop. Based on a hierarchical cluster analysis, we have identified three groups of customers: “loyal customers who buy regularly”, “occasional customers with smaller orders” and “new customers”. Now, when a new customer makes a purchase in the shop, we use a classification model that is based on predefined characteristics (e.g. frequency of purchases, value of orders) and assigns this customer to the appropriate group. This allows us to tailor marketing offers, promotions or loyalty programmes for each of these customer groups according to their characteristics and preferences.
Table 1. Division of segmentation techniques.
GROUPING TECHNIQUES
Clustering, also known as cluster analysis, is a data analysis technique aimed at dividing a set of objects into smaller, more homogeneous groups, based on certain criteria of similarity or proximity. Objects within each group are more similar to each other than to objects outside that group, allowing meaningful data structures to be extracted.
The main clustering algorithms include:
1. The k-means algorithm
The k-means algorithm is a popular clustering algorithm that assigns objects to clusters by minimising the sum of the squares of each object’s distance from the centre of the cluster (centroid). The algorithm starts by selecting initial centroids and then iteratively assigns objects to the nearest clusters and updates the positions of the centroids. This process continues until convergence is reached. It is worth bearing in mind that this type of clustering technique requires the number of clusters to be specified before analysing the dataset.
2. Hierarchical algorithms
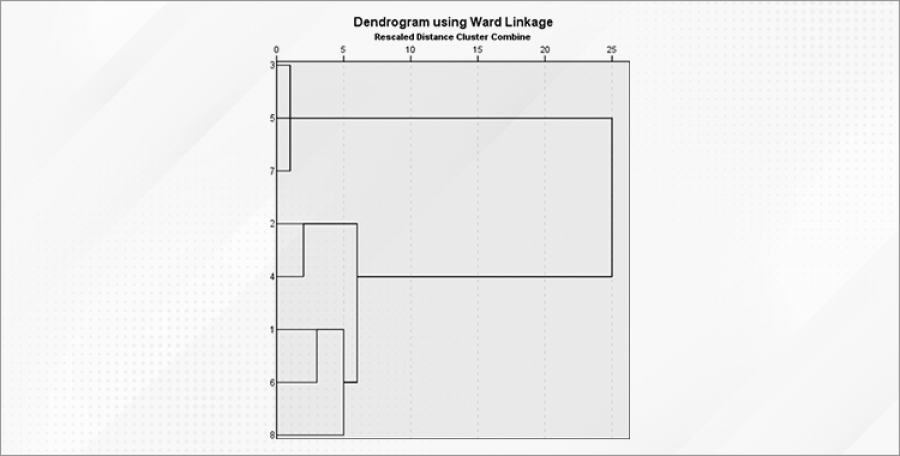
Another popular algorithm within segmentation is hierarchical clustering, which creates a hierarchy of clusters (groups) in the form of a tree, called a dendrogram. The algorithm starts with individual objects as separate clusters and gradually combines them into larger clusters based on the similarity between them. Two approaches can be distinguished within this clustering technique:
- An agglomerative approach, in which the clustering process starts by creating a separate cluster for each object and then iteratively merges the closest clusters that have the smallest distance between them. In each object merging step, a larger cluster is created until all objects are merged into one large cluster or a certain number of clusters is reached.
- A deglomerative approach that works inversely to the agglomerative approach. It starts with one large cluster containing all objects and iteratively divides it into smaller clusters based on the distance between objects. In each splitting step, objects form smaller clusters until a certain number of clusters is reached or stopping conditions are met.

Figure 1. Example dendrogram as a result of one of the hierarchical clustering techniques.
3. Density clustering algorithm
The Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm is a cluster analysis technique that is based on identifying clusters of data based on the density of points in space. Unlike other clustering algorithms, DBSCAN does not require a predetermined number of clusters, which makes it flexible and easy to apply. The algorithm distinguishes core, boundary and noise points, allowing for accurate detection of a variety of data structures. DBSCAN is particularly useful for datasets with variable shapes and densities and can effectively deal with outlier points.
CLASSIFICATION
Classification is a way of analysing data with the primary aim of predicting the value of a particular variable from a set of data. In general, the purpose of classification is to assign a given observation to a predefined group (e.g. buy – don’t buy; belongs to group A, B or C, etc). The analysis involves building an equation, set of equations or rules to assign observations from individual variables to a given group determined by the explained variable. In classification, the explained variable is precisely the membership of a particular group (segment). As a result of using classification techniques, we want to obtain an answer to the question of which variables and which values or ranges of values influence membership of a particular group. An example of a classification result could be the decision rule for granting a credit card: “if the age of the bank customer is less than 25 or the bank account income is less than PLN 5,000 , the risk is high”. If the customer meets one of the criteria, he or she will be assigned to the high credit risk category. Classification algorithms are used in many fields, such as trend recognition in financial markets or decision support in banking credit processes. In medicine, they can be used to classify various conditions based on medical data, allowing patients to be automatically diagnosed.
Figure 2. Example of a decision tree as a result of one of the classification techniques.
SUMMARY
Segmentation is a key process in data analysis for dividing a large dataset into smaller, more homogeneous groups or segments based on specific criteria. The purpose of segmentation is to identify hidden patterns, differences and similarities between objects in a dataset, enabling more precise and relevant analyses. Cluster analysis and classification are key tools in data analysis, allowing for a better understanding of data, identification of relationships and more accurate decision-making in various fields such as marketing, economics, medicine and social sciences.